EA(自動売買)もAIを使った方が勝てますよね?

いいえ。FXの自動売買では、AIを使う方がリスクが高くなる可能性があります。
理由は、AIは「当たったように見える設定」を作りやすく、過剰最適化や再現性の問題が起きやすいからです。
じゃあ「AI搭載EA」って書いてあるだけで避けた方がいいんですか?
結論:避けるべきなのは「AI」ではなく、検証できないEAです。
見るべきは “AIかどうか” ではなく、優位性の検証手順・再現性(ライブで同じ挙動か)です。

AI自動売買(AIトレーディング)は危険?「AI=勝てる」と思う前に知っておくべきこと
AIという言葉と、教科書のように右肩上がりのバックテスト(BT)を見ると、思わず「これが聖杯かも」と信じたくなります。
でも、その“きれいすぎる成績”の裏には、誇大広告やバックテストだけが強いEAが混ざっていることがあります。
また、短期のフォワードテスト(短期間の実運用テスト)が良くても、リアル口座では崩れる──これは珍しい話ではありません。
関連記事:EAとは?FX自動売買の仕組みと選び方を徹底解説|EA完全ガイド
結論:AIを使っても勝てるわけではない
AI(機械学習・大規模言語モデル/LLM)を使ったトレーディングは魅力的です。
しかし、AIを使っただけで勝てるようになるわけではありません。
むしろ、検証手順や「同じ条件で同じ結果が出るか(再現性)」の設計を誤ると、通常のEAよりリスクが大きくなることもあります。
AIトレーディングが危険になりやすい3つの理由
- 機械学習EAは「当たったように見せる」のが簡単
特徴量(入力データ)の組み合わせ次第で、過去データにだけ都合よく合う設定が作れてしまいます。
その結果、過剰最適化(オーバーフィッティング)が起きやすく、「過去では完璧でも、未来では通用しない」状態になりがちです。 - LLM接続型EAはバックテストで再現・検証しづらい
LLMは外部APIを使うことが多く、出力が毎回同じとは限らない(非決定性)うえに、遅延や利用制限、エラーの影響も受けます。
そのため、バックテストで「実運用と同じ条件」を再現しにくいのが弱点です。 - 「LLM対応EA」でも、バックテストとライブでロジックが別の可能性
とくに重要なのは、MT5のストラテジーテスター(バックテスト)では、外部API通信が制限されるため、LLM連携をそのまま再現できないケースが多いことです。
この場合、バックテストを代替ロジック(テスター用)で動かしている可能性があります。
もし代替ロジックがグリッドやマーチンゲールのような手法だと、短期の成績は“負けにくく”見せやすい一方で、相場急変時に大きな損失につながるリスクがあります。
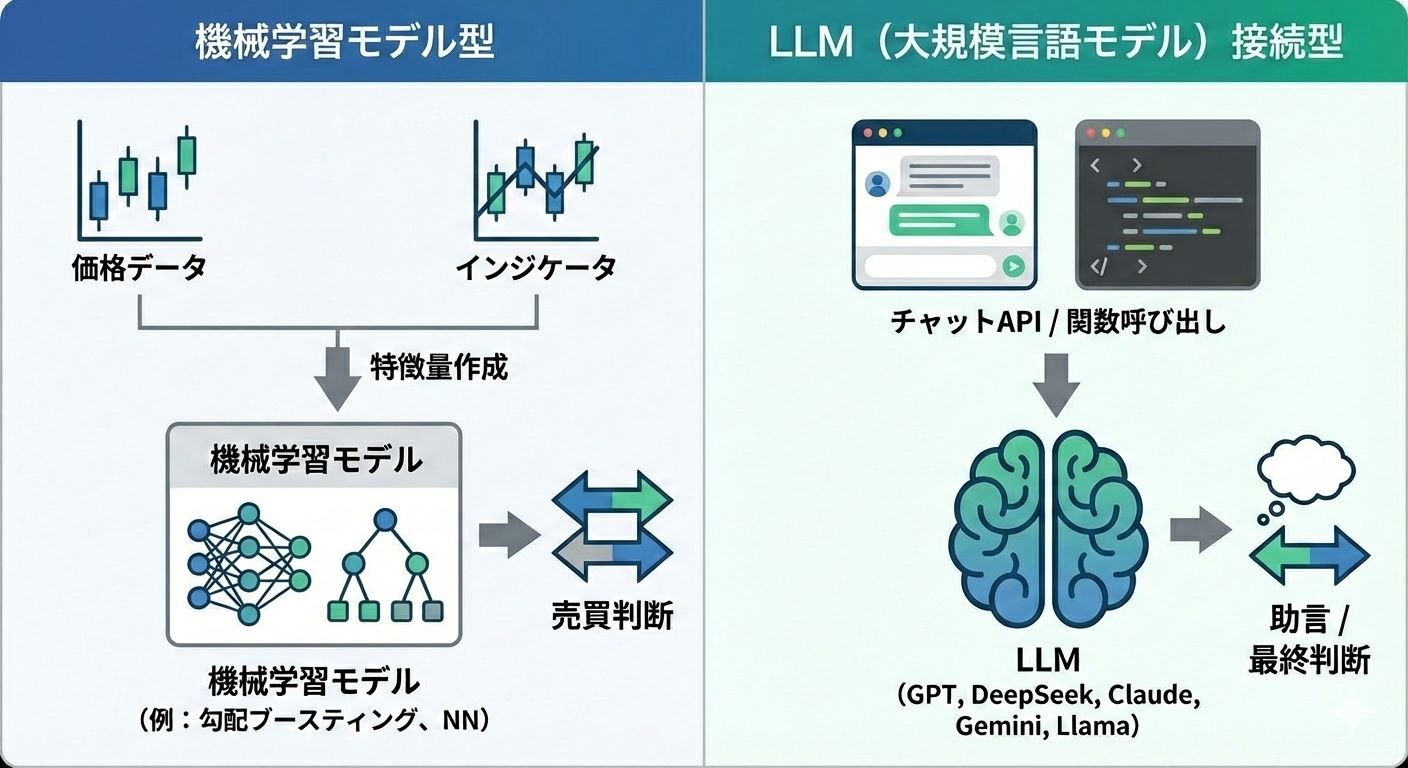
AI自動売買(AIトレーディング)の種類:機械学習EAとLLM連携EA
AIを使った自動売買(EA)は、大きく分けて2種類あります。
見た目はどちらも「AIで判断」ですが、仕組みと検証の難しさがまったく違います。
機械学習モデル型(機械学習EA)
価格データやテクニカル指標、経済イベントなどから特徴量(入力データ)を作り、
学習したモデル(例:勾配ブースティング、ニューラルネットワーク等)で売買判断を出すタイプです。
注意点:機械学習モデルは、過去の相場に柔軟に適合しすぎて未来の相場では通用しない過剰最適化(オーバーフィッティング)が起こりやすいです。
LLM(大規模言語モデル)連携型(API接続型EA)
チャットAPIなどを介してOpenAIのGPTやDeepSeek、Google GeminiなどのLLMに接続し、
相場の要約・シグナル提案・売買判断の補助(または最終判断)をさせるタイプです。
注意点:外部APIは利用制限・遅延・出力の揺れ(非決定性)があるため、MT5のバックテストで「実運用と同じ条件」を再現しにくく、検証が難しいです。
通常EAと機械学習EAの違い:仕組み・最適化・再現性
「通常のEA(インジケータのルール型)」と「機械学習EA(モデル型)」は、勝ち方というより
作り方(最適化の対象)が違います。ここを理解すると、バックテストがきれいすぎるEAの危険性も見抜きやすくなります。
| 観点 | 通常のEA(インジ組合せ) | 機械学習EA(特徴量→モデル) |
|---|---|---|
| 中核ロジック | インジケータのシグナル条件をルール化 | 特徴量から統計モデルが関係性を学習 |
| 最適化対象 | インジのパラメータ・閾値 | 特徴量の設計・前処理・モデル構造・ハイパーパラメータ |
| 過剰最適化のリスク | 存在(パラメータの過剰調整) | より高い(調整できる範囲が広く、当たり設定を引きやすい) |
| 検証の難易度 | 比較的把握しやすい | データリーク(先見)や分割方法の罠に注意が必要 |
| 再現性 | 固定ルールで再現しやすい | 学習データ・シード・実装差で結果がぶれやすい |
補足:機械学習EAは「ツマミ(調整できる要素)」が多い分、上手くハマると強く見えますが、
同時に偶然の当たりも拾いやすくなります。次のセクションでは、なぜ過剰最適化が起きやすいのかを具体的に解説します。
機械学習EAが過剰最適化(オーバーフィッティング)しやすい理由
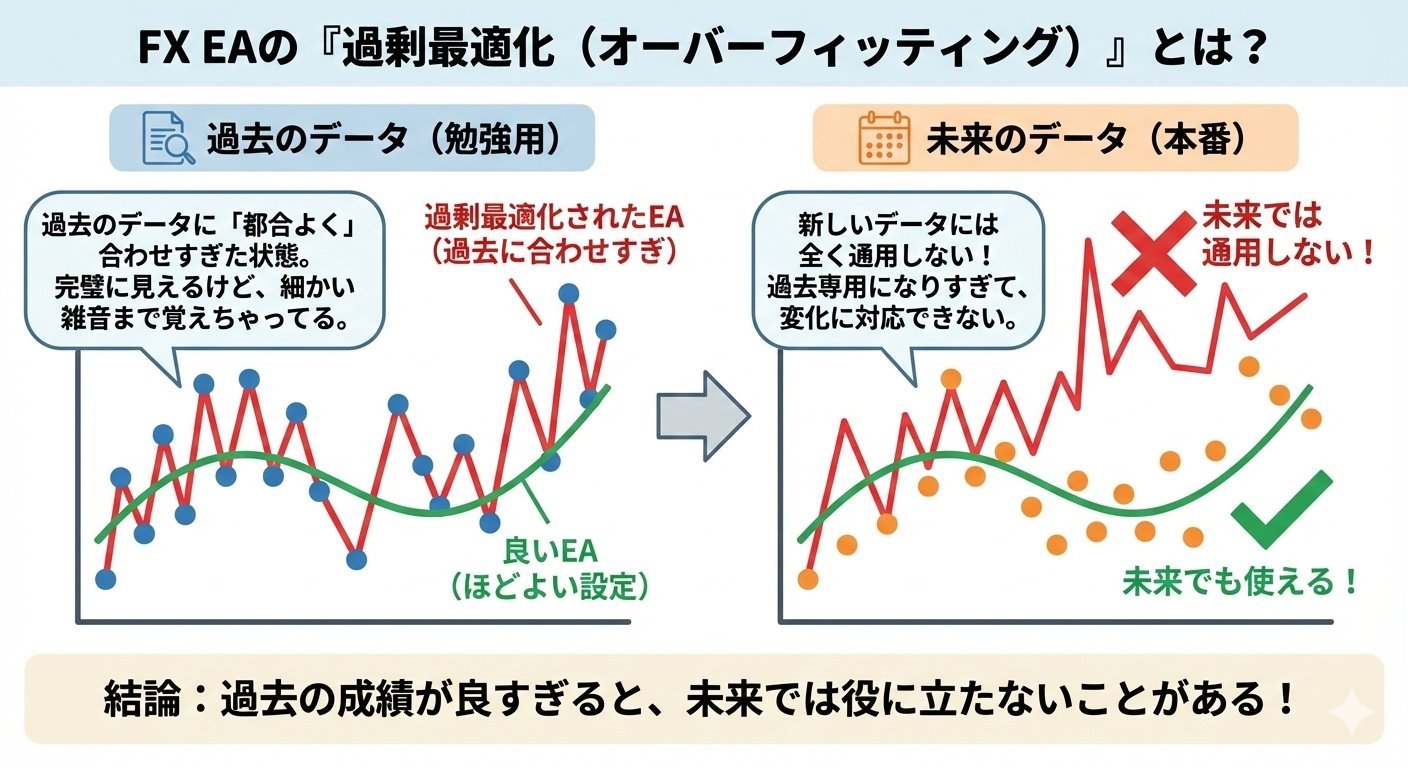
過剰最適化(オーバーフィッティング)のイメージ。過去データに合わせすぎると、未来(フォワード)で通用しなくなる。
まず「過剰最適化(オーバーフィッティング / overfitting)」とは、
過去のデータにだけ都合よく当てはまりすぎて、将来(未知のデータ)では通用しなくなる状態のことです。
関連記事:EAの過剰最適化(オーバーフィッティング)とは?見抜く方法と購入前チェックリスト
イメージは過去問の答えを丸暗記する勉強に近いです。
過去問では満点でも、問題の出し方が少し変わると急に点が取れない。
相場も同じで、「過去の特定期間にだけ効いたクセ(偶然)」まで学習してしまうと、
フォワード(未来)で崩れやすくなります。
過剰最適化は“起きやすい現象”:機械学習モデルは合わせ込めてしまう
機械学習では、過剰最適化(オーバーフィッティング)はバグというより“起きやすい自然現象”です。
理由はシンプルで、機械学習のモデルは「成績が良くなるように」学習し続けるため、
放っておくと本質(再現性のある規則)だけでなく偶然(ノイズ)まで拾ってしまうからです。
ここでいう機械学習のモデルとは、ざっくり言うと「入力(特徴量)から売買判断を出すための計算ルールのかたまり」です。
従来からあるインジケータを利用するEAが「RSIが30以下なら買い」のように人が決めた条件で動くのに対して、
機械学習モデルは、過去データから“当たりやすい条件の組み合わせ”を自動で探して学習します。
通常のインジケータEAの最適化は、たとえば「移動平均の期間」「RSIの閾値」などパラメータの組み合わせを調整するイメージです。
一方で機械学習モデルは、特徴量の作り方(どの指標を使うか・どう加工するか)や、モデル構造・重みなど、
調整できる“つまみ”が圧倒的に多く、しかも複雑な条件(例:複数の指標×時間帯×ボラ×相関…)にも柔軟に対応できます。
この「柔軟さ」は強みでもありますが、同時に過去データにだけピッタリ合う“都合の良いルール”も作れてしまいます。
つまり、モデルは成績を上げるために、偶然のクセ(ノイズ)まで“学習してしまう”ことがある。これが過剰最適化が起きやすい理由です。
機械学習EAで過剰最適化が起きやすい3つの理由(初心者向けに要点だけ)
- モデルが「合わせ込み」できてしまう
機械学習モデルは、人が決めた単純なルールよりも複雑な条件に対応できます。これは強みですが、
その分過去データにだけピッタリ合う都合のいいルールまで作れてしまい、未来で崩れやすくなります。 - 試行回数が増えるほど「偶然の当たり」を拾う
特徴量、前処理、モデル、パラメータ…と試す数が増えるほど、たまたま良かった設定が見つかります。
それは「本当に強い」より、宝くじの当たりを引いた可能性もある、という点が落とし穴です。 - 検証のやり方次第で成績は簡単に盛れてしまう
未来の情報が混ざる(データリーク)/時間順を壊して評価する/同じ期間で何度もテストする…などがあると、
バックテストは実力以上に良く見えます。相場は時系列なので、ここは特に注意が必要です。
補足:相場は金利・ボラ・参加者の変化で状況が変わります(非定常)。
そのため「過去で良かった=未来でも良い」とは限りません。
過剰最適化(オーバーフィッティング)の「よくあるサイン」
- バックテストだけ異常にきれい(右肩上がりが不自然、ドローダウンが小さすぎる)
- 設定を少し変えるだけで成績が激変(頑健性がない)
- 期間や銘柄を変えると崩れる(再現性が弱い)
- 説明できないのに数字だけ良い(偶然適合の可能性)
LLM接続型EA(GPTなど)の注意点:MT5バックテストで検証しにくい5つの理由
近年、OpenAIのGPTをはじめ、DeepSeek、Anthropic Claude、Google Gemini、Meta Llama系APIなど、
チャットAPIや関数呼び出し(Tools / Function calling)を使って
LLMに相場の助言(シグナル提案)や判断の一部を任せるEAが増えています。
ただし大前提として、LLMは言語モデル(文章を生成する仕組み)です。
「この戦略は期待値がプラス」と統計的に計算し、保証してくれる装置ではありません。
そのため、LLMが提案した売買が本当に有利かどうかは、長期バックテスト・フォワードテスト・取引コスト込みで別途検証する必要があります。
さらに実務上の問題として、LLMは外部APIを呼び出すケースが多く、MT5のストラテジーテスターでは
外部通信の扱い・遅延・レート制限などをライブと同じ条件で再現しにくいため、
そもそもバックテストで優位性を検証しづらいのも難点です。
LLM接続EAの基本フロー(全体像)
MT5/EA ↓(価格取得) 前処理(指標計算・状態判定) ↓(APIリクエスト) LLM(文章/JSONで回答:提案・理由・条件など) ↓(パース) EA側で機械的チェック(ルール/リスク/整合性) ↓(最終判断) 注文(ロット・SL/TP・許容スリップ等) ↓ 監視(約定確認・例外処理・ログ保存・フォールバック)
ポイント:安全性と再現性のために、LLMの出力をそのまま発注に直結させない設計が基本です。
「LLMは提案まで」→「EA側が固定ルールで採否を決める」と分離した方が、事故が起きにくくなります。
注意点1:LLMは統計的優位性の検証には不向き
前述のとおり、LLMは言語モデルであり、統計検定や期待値計算の信頼できる“証拠”を自動で出してくれる存在ではありません。
たとえば「このルールで1000回トレードしたら損益やドローダウンはどうなるか」を、
正確な前提で計算し、再現性のある形で示すのは本来バックテストや統計の領域です。
LLMは説得力のある説明が得意ですが、“それっぽい説明=期待値がある”とは限らない点に注意してください。
結論として、LLMの返答はアイデアであって、証拠ではありません。
注意点2:再現性の問題(同じ条件でも出力が揺れる)
プロンプトの微差、設定(temperature等)、モデル更新(アップデート)などで、回答が変わることがあります。
その時々で判断が揺れると、トレード結果も変わるため、「同じ条件で同じ検証ができない」問題が出ます。
注意点3:実運用では遅延・エラー・価格ズレが致命傷になり得る
外部APIを挟む以上、ライブ運用では遅延(レイテンシ)と通信エラーが必ず発生します。
そしてEAでは、この“数秒のズレ”が結果を大きく変えます(特にスキャルピング系)。
- API遅延:応答待ちの数秒〜十数秒で価格が動き、想定したエントリー条件が崩れる
- タイムアウト/障害:判断が空白になり、「発注する/しない」自体が不安定になる
- バックテストとの差:テスターは“時間を飛ばして進む”ため、同じ遅延の影響を再現しにくい
注意点4:出力の安全性(ハルシネーション/フォーマット崩れ/暴走)
LLMは、分からない状況でも無理に回答を作る(ハルシネーション)ことがあります。
また、JSON設計でも欠損・型違い・想定外の値が起こり得ます。トレードではこれが損失に直結します。
注意点5:運用コストと仕様変更(料金・レート制限・突然の挙動変化)
LLM APIは、運用中に料金やレート制限、仕様が変わることがあります。
その結果、「突然コストが上がる」「レスポンスが遅くなる」「制限に当たって停止する」など、運用面の揺れが起こり得ます。
また、APIキーの扱いも重要です。EA内に直書きすると漏洩リスクが高く、
最悪の場合、第三者に悪用されて課金被害や停止につながる可能性があります。
まとめると、LLM接続型EAは「アイデア生成・補助判断」には強い一方で、期待値の検証・再現性・実運用の安定性に落とし穴があります。
だからこそ、LLMが万能ではないという視点を持つことが大切です。
MQL5ストアの「AI/LLM接続EA」は要注意:バックテストが信用できない理由
最近のMQL5ストアでは「GPT」「DeepSeek」などのLLM API接続をうたうEAが増えています。
ただし重要なのは、“AI/LLM接続”は勝てる根拠ではなく、検証の透明性がすべてという点です。
とくに外部API連携は、MT5のストラテジーテスターでライブ同一条件を再現しにくいことがあり、
バックテストがテスター用の代替ロジックで作られている可能性も出てきます。
なぜ「MT5のバックテストでLLM連携を検証できない」ケースが多いのか
- 外部通信(HTTP/HTTPS)が制限される/不安定になりやすい
テスターは高速に過去データを処理しますが、外部APIはリアルタイム通信が前提です。
速度、制限、エラー挙動がライブと一致しません。 - 遅延(レイテンシ)の影響を再現しにくい
ライブではAPI応答待ちの数秒〜十数秒で価格が変わることがあります。
しかしテスターは「時間を飛ばして進む」ため、同じ遅延の影響が反映されにくいです。 - レート制限・料金・障害など“現実の運用条件”が入ってこない
ライブでは「混雑で遅い」「一時的に落ちる」「回数制限に当たる」などが起きます。
テスターの結果は、それらを含まないことが多いです。
このため、開発者が「テスターでは外部APIを使えない(使わない)」設計にすると、
バックテスト用ロジックとライブ用ロジックが分離しがちです。
そしてこの分離が説明されない場合、購入者は“同じEAの検証結果”だと誤解してしまいます。
要注意:AIに接続していても「バックテストだけ別戦略」で強く見せるのは簡単
「AIに接続している」と言いつつ、バックテストではグリッド/マーチンゲール系の戦略を動かしておけば、
短期の成績を“負けにくく、あたかもAIが相場を完全に予測しているように見せかける”ことは比較的簡単です。
特に、きれいすぎる右肩上がりでドローダウンが極端に小さい場合は要注意です。
「AIの力」ではなく、ナンピン・ロット倍掛け・ポジション積み上げで曲線を整えている可能性を疑うべきです。
とくに危険:グリッド・マーチンゲールの“見た目の良さ”に注意
グリッドやマーチンゲールは、短期的に負けにくく見せられる反面、
ポジションの累積と含み損の膨張により、相場急変で一度に致命傷になり得ます。
ボラティリティ拡大やスプレッド拡大が重なると、最悪の場合口座破綻につながるリスクがあります。
関連記事:
マーチンゲールEAに騙されるな:口座破綻の危険性と見分け方【検証】
ナンピン(グリッド)EAに騙されるな – 口座破綻の危険性と見分け方【自作EAで検証】
まず押さえるべき重要ポイント
- 「AI/LLM=勝てる」ではない
LLMは文章生成が得意でも、期待値(勝てる根拠)を保証しません。勝てるかはデータ検証が必要です。 - バックテストは「何のロジックで動いたか」が命
LLM連携がテスターで再現できない場合、バックテストは別ロジックの可能性があります。ここが不透明なら危険です。 - 売買判断の最終責任がどこにあるか
「LLMが決める」のか「EA側の固定ルールが決める」のかで、再現性と安全性が大きく変わります。
良いEAを見分ける基準(AI活用の有無に関係なく共通)
ここでは「AIを使っているかどうか」に関係なく、良いEAを見分けるための共通基準を整理します。
初心者が陥りやすいのは、派手な数字(勝率・右肩上がり・短期の爆益)に引っ張られてしまうことです。
しかし、長期で生き残るEAはむしろ逆で、地味でも崩れにくい堅守(ロバスト)な設計を持っています。
以下の基準は「AI/LLMだから安心」「AI/LLMだから危険」という話ではなく、結局は検証と設計の品質がすべてという前提でのチェック項目です。
1. 長期バックテストで崩れないか(環境が変わっても耐えるか)
相場にはトレンド相場・レンジ相場・高ボラ相場・低ボラ相場など環境の違いがあります。
良いEAは、特定の期間だけ強いのではなく、環境が変わっても致命傷を受けにくい傾向があります。
- 資産曲線が右肩上がりでも、破綻級のドローダウン(DD)がないか
- 一部期間の好成績だけで成り立っていないか(特定期間の稼ぎ依存がないか)
- ボラ急変や相場の切り替わりで、損失が拡大しすぎていないか
- 他の通貨ペアでテストして、結果が悪すぎないか
関連記事:MT5バックテストの見方:EA評価は設定・有効証拠金DD・トレード履歴で見抜く
2. ライブ口座のフォワードテストがあるか(リアル口座+継続公開)
バックテストは過去データ上のシミュレーションで、スリッページ・約定拒否・スプレッド拡大・遅延などを完全には再現できません。
だからこそ、実口座または第三者の監視下での継続フォワードが重要です。
- デモではなく実口座か(理想は実口座)
- 短期だけの公開ではなく、継続して更新されているか
- Myfxbook等で改ざんしにくい形で公開されているか
関連記事:Myfxbookの見方:EAのリスクと再現性を見抜くチェック手順(Balance/Equity・Margin・履歴)
3. リスクリワード(RR)が健全か(勝率より大事)
EA評価で重要なのは勝率単体ではなく、勝率 × 平均利益 × 平均損失のバランスです。
勝率が高くても、1回の負けが大きい(損大利小)構造だと、長期では一撃で崩れやすくなります。
- 平均損失が極端に大きくないか(小さな勝ち+たまに大負けは危険信号)
- PFが良くても、DDや損益分布が歪んでいないか
- 「損切りが遅い」設計になっていないか
- ナンピン(グリッド)やマーチンゲールなど一撃で大きな損失を出す手法が採用されていないか
4. 再現性があるか(特にスキャルピングEAは要注意)
特に、「ごくわずかなpips」を狙うスキャルピングEAの結果は取引環境によって大きく左右されます。
スプレッド・手数料・スリッページで成績が崩れやすく、さらにブローカーの約定方式やレイテンシの影響も大きいです。
バックテストやデモ口座の成績がリアル口座で再現されないケースが多いので注意が必要です。
関連記事:スキャルピングEAは勝てる?おすすめしない理由(再現性の低さに注意)
まとめ
AIは強力な道具ですが、万能鍵ではありません。
機械学習EAは過剰最適化の罠に陥りやすく、LLM接続EAは検証と再現性の設計が難しい。
だからこそ、評価軸は「AIかどうか」ではなく、長期バックテスト・ライブでのフォワード・健全なRR・再現性という
“地味だけど効く基準”に置くべきです。
派手な宣伝文句よりも、検証の透明性と壊れにくい設計を重視してください。
その積み重ねが、AIの有無に関係なく「長く生き残るEA」を見極める最短ルートになります。
関連記事:EAのロバストネス(堅牢性)とは?崩れにくいEAの選び方と購入前チェックリスト
FAQ
- Q. AIを使えば必ず勝てますか?
- A. いいえ。AIは設計と検証が不十分だと、むしろリスクを増幅します。期待値の源泉と再現性を確認しましょう。
- Q. LLM接続EAはバックテストできますか?
- A. 標準環境では外部API挙動の再現に制約があり、そのままの検証は難しい場合が多いです。代替ロジックや検証手順の明示が不可欠です。
- Q. 良いEA選びで最も大切なことは?
- A. AIの有無ではなく、長期バックテスト・ライブのフォワード・健全なリスクリワード(RR)という基本3点の一貫性です。堅守性(ロバストネス)を最も重視すべきです。